Atención en Memoria Analógica: LLMs más rápidos que en GPU
Los LLMs en la actualidad dependen de la autoatención, en GPUs mover el KV-Cache entre memorias es el mayor cuello de botella de rendimiento, realmente no es el computo. Cuando cada token se reescribe y se lee toma demasiada energia y tiempo.
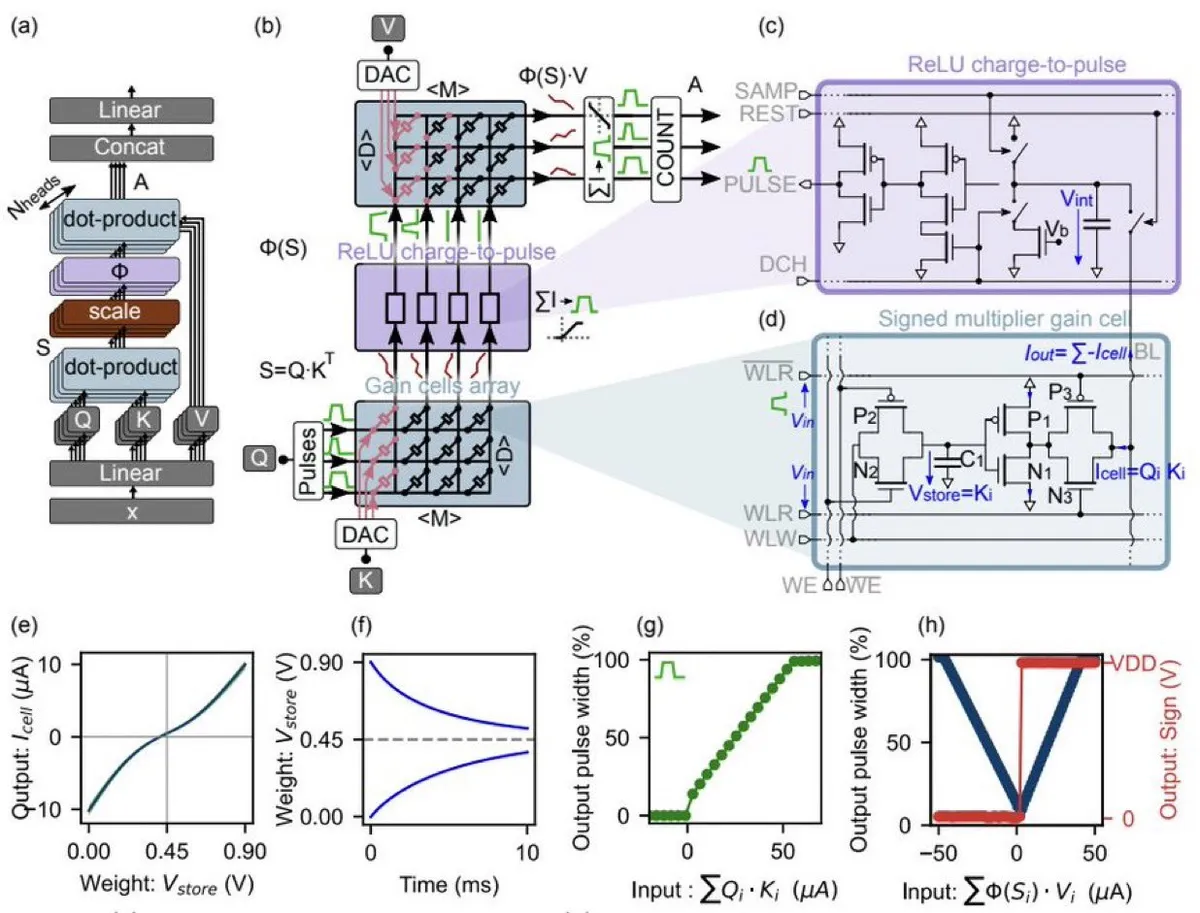
Un equipo de Jülich/RWTH presenta en un reciente paper una arquitectura de autoatención para Transformers que mueve el cálculo del Kv-cache, usando “gain cells” (memorias analógicas basadas en carga) para almacenarlos y computar los dos productos punto de la atención en el dominio analógico, evitando traslados de datos y ADCs convencionales. El resultado que se obtuvo en simulación, fue reducir hasta 2 órdenes menos de latencia y 5 órdenes menos de energía que en GPUs, en la parte de atención. Los investigradores mapean GPT‑2 a este hardware con un algoritmo de adaptación sin reentrenar desde cero y alcanzan resultados comparables.
¿Por qué es tan rápido?
- Paralelismo masivo, muchas celdas suman a la vez.
- Sin conversiones pesadas a digital en cada paso, señales simples que representan “cuánto” en lugar de bits moviendose a través de las GPUs.
- Mantener el KV‑cache en el chip, que es donde ocurre la operación.
Modelos:
- No hace falta reentrenar los modelos desde cero. Ajustan un GPT‑2 con un truco de inicialización que compensa imperfecciones analógicas.
- Cambian softmax por una función más simple y limitan la ventana de contexto para que todo sea más ligero, sin perder resultados prácticos (Por el momento).
Resultados que se mostraron en el paper:
- Hasta 100× más rápido por token.
- Hasta 100,000× menos energía que GPUs de referencia.
Riesgos y realidad
- Son resultados en simulación para la parte de atención, no para todo el Transformer.
- La integración híbrida analógico‑digital puede generar bugs raros, que deben ser solucionados.
¡Muchas gracias por leer hasta aqui! El equipo también ha mostrado como hacerlo caseramente, si tienes los recursos y deseas correr el mecanismo de atención de un LLM de manera análoga es momento de que lo intentes :)
Lecturas y recursos
- Paper: Analog In-Memory Computing Attention Mechanism for Fast and Energy-Efficient Large Language Models — Paper
- Replicación software (simulación del hardware): el repositorio indicado en el paper describe scripts y modelos.